AI
Insights from Unstructured Data: Oracle Analytics and AI Document Understanding
When we think about business data, we usually picture tidy tables and dashboards neatly populated with structured relational data. But in reality, much of an organisation’s most valuable information lives in…

When we think about business data, we usually picture tidy tables and dashboards neatly populated with structured relational data. But in reality, much of an organisation’s most valuable information lives in unstructured formats—scanned invoices, PDFs, handwritten notes, and contracts. This data is often locked away in silos, disconnected from the wider analytical ecosystem.
Oracle Analytics’ AI Document Understanding feature changes that. It enables organisations to automatically extract structured data from documents stored in OCI Object Storage using pretrained AI models—all without needing a data science team. With this capability, you can enrich dashboards with data that would previously be too costly or complex to access.
In this post, we’ll walk through:
- What the AI Document Understanding feature is
- Practical business scenarios where it is applicable
- Step-by-step setup and configuration, including OCI policy management and model registration
- Tips and tricks for working with unstructured data in Oracle Analytics
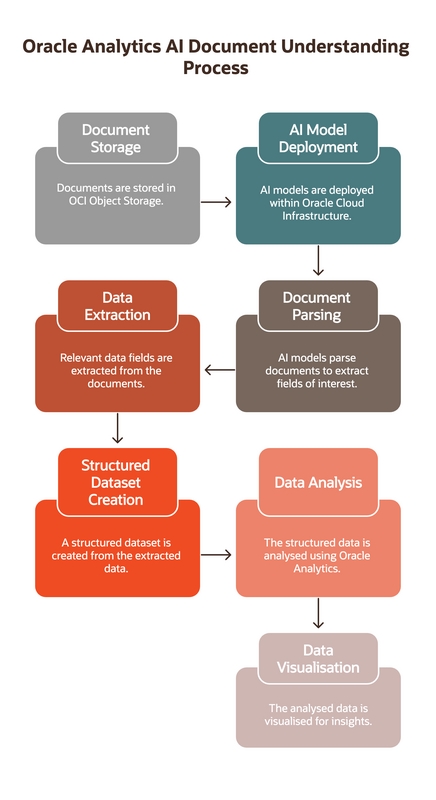
What Is Oracle Analytics AI Document Understanding?
At its core, the AI Document Understanding capability in Oracle Analytics leverages AI models (deployed within Oracle Cloud Infrastructure) to parse and extract fields of interest from documents stored in OCI Object Storage. This is particularly powerful for automating workflows that currently depend on manual data entry or semi-structured file formats.
It supports a range of document types and layouts, including:
- PDF invoices from suppliers
- Utility bills or receipts
- Financial statements
- Handwritten or printed forms (subject to OCR accuracy)
The output is a structured dataset—columnar data ready for blending, analysis, and visualisation in Oracle Analytics.
IAM Policies
To enable Oracle Analytics to securely access documents stored in OCI Object Storage and to invoke AI services like Document Understanding, specific IAM policies must be in place. Without these policies, your OAC instance won’t have the necessary permissions to read documents or trigger AI model processing. In this section, we’ll walk through the exact tenancy- and compartment-level policies required, ensuring your setup is both functional and secure. You can find more information here.
The following IAM policies grant Oracle Analytics the necessary permissions to read from your Object Storage bucket and to invoke the AI Document Understanding service.
Allow group <GROUP NAME> to use ai-service-document-family in compartment <COMPARTMENT NAME>
Allow group <GROUP NAME> to manage ai-service-document-document-job in compartment <COMPARTMENT NAME>
Allow group <GROUP NAME> to manage ai-service-document-processor-job in compartment <COMPARTMENT NAME>
Allow group <GROUP NAME> to read buckets in compartment <COMPARTMENT NAME>
Allow group <GROUP NAME> to manage objects in compartment <COMPARTMENT NAME> where target.bucket.name='<BUCKET NAME>'
Allow group <GROUP NAME> to read objects in compartment <COMPARTMENT NAME> where target.bucket.name='BUCKET NAME'
Compartment level IAM Policy
Allow group <GROUP NAME> to use ai-service-document-family in compartment <COMPARTMENT NAME>Allow group <GROUP NAME> to manage ai-service-document-document-job in compartment <COMPARTMENT NAME>Allow group <GROUP NAME> to manage ai-service-document-processor-job in compartment <COMPARTMENT NAME>Allow group <GROUP NAME> to read buckets in compartment <COMPARTMENT NAME>Allow group <GROUP NAME> to manage objects in compartment <COMPARTMENT NAME> where target.bucket.name='<BUCKET NAME>'Allow group <GROUP NAME> to read objects in compartment <COMPARTMENT NAME> where target.bucket.name='BUCKET NAME'XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
Notes
- Replace <GROUP NAME> with your OCI IAM Group name
- Replace <COMPARTMENT NAME> with your OCI Compartment name where you Object Storage bucket is located in your OCI tenancy
- Replace <BUCKET NAME> with your Object Storage Bucket name where your files have been uploaded to. Note that the Bucket Name is in single quotes.
Next policy needs to be defined at the root compartment level
Allow group <GROUP NAME> to read objectstorage-namespaces in tenancy
Root level IAM Policy
Allow group <GROUP NAME> to read objectstorage-namespaces in tenancyXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
These policies are necessary to enable Oracle Analytics to access the OCI AI Document Understanding model. Without these policies correctly setup, you will encounter errors when you attempt to run your data flow in Oracle Analytics.
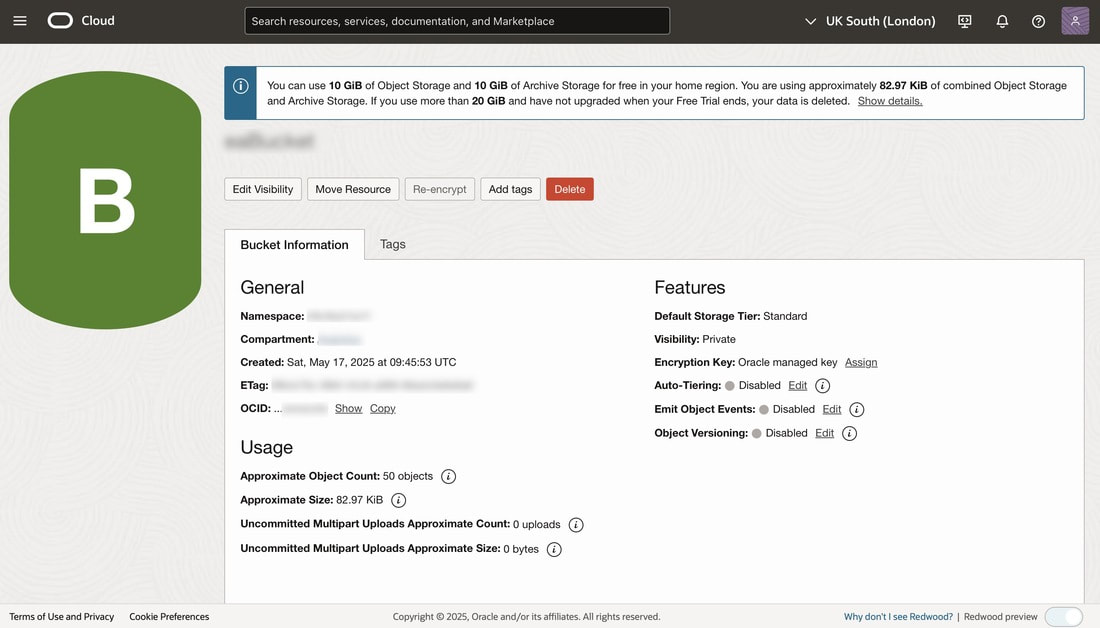
With the IAM policies configured, you can now proceed with setting up the connection and registering the model within Oracle Analytics.
You do this by creating an Oracle Analytics connection to your Oracle Cloud Infrastructure tenancy that will enable you to gain access to your OCI Object Storage Bucket.
Register a pre-trained Document Key Value Extraction model with your Oracle Analytics instance ensuring that the bucket created previously is selected.
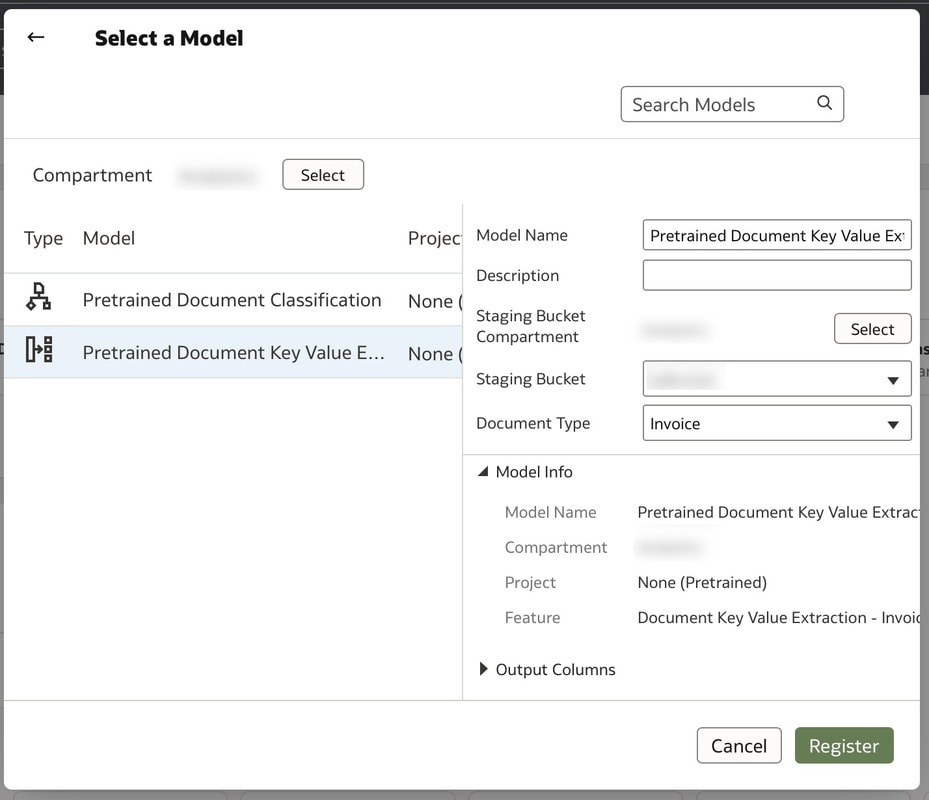
This completes all prerequisites and the next step is to run the newly registered pre-trained model in Oracle Analytics by creating a data flow.
The next step is to create a create a "dataset" which is used as an input to the data flow. This dataset is a CSV file that contains the OCI object storage bucket URL where the documents have been uploaded to.
This CSV file can either contain a row for each document with a URL for each document that you intend to process or a single row with a URL for the bucket itself. This way every document within this bucket will be processed. Personally, it's a no brainer for me to use the second option. As mentioned earlier in this article, you need to derive the bucket URL by logging on to the OCI console's bucket details page and copying the URL from your browser. You can see a sample below that has 2 tabs; the 1st tab is what you would use for option 1 where you list out your documents with their corresponding URLs. The 2nd tab has a single row and this is what you would use to instruct the data flow to process all documents within the specified bucket.
| Template Bucket URL dataset | |
| File Size: | 10 kb |
| File Type: | xlsx |

|

|
Follow the instructions here to create your data flow.
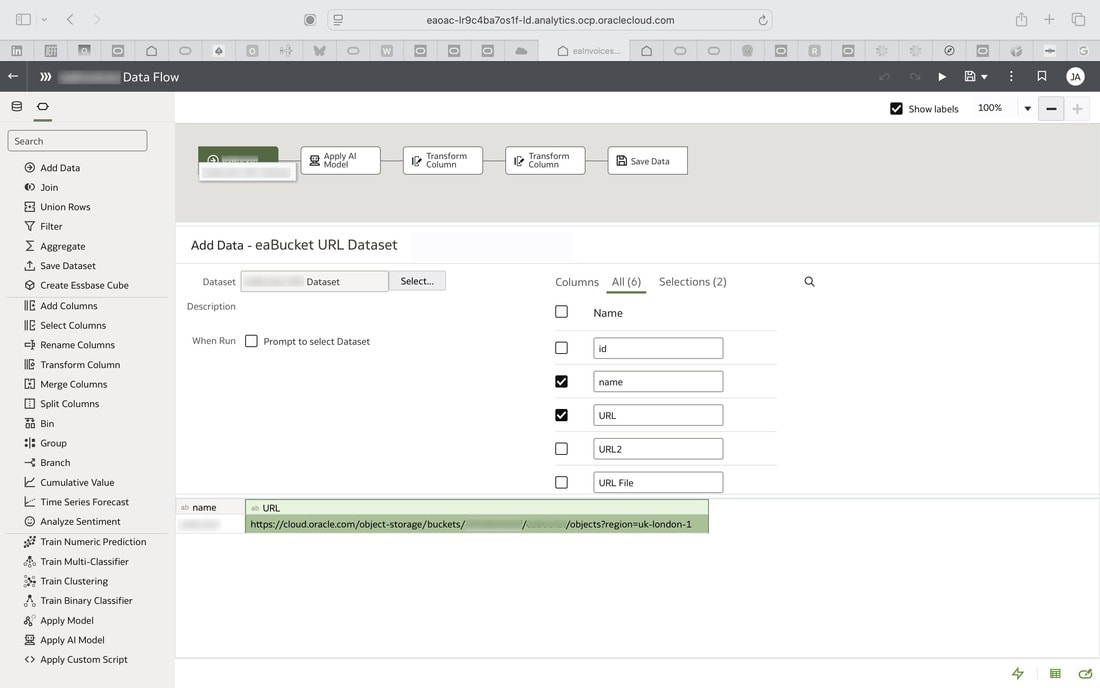
Using the Apply AI Model step, you make a call the the registered pretrained AI Document Understanding model. You then add a Save Data step in which you specify the output dataset. In my example below, I have a few Transform Column steps which are being used to execute some transformations to some columns.
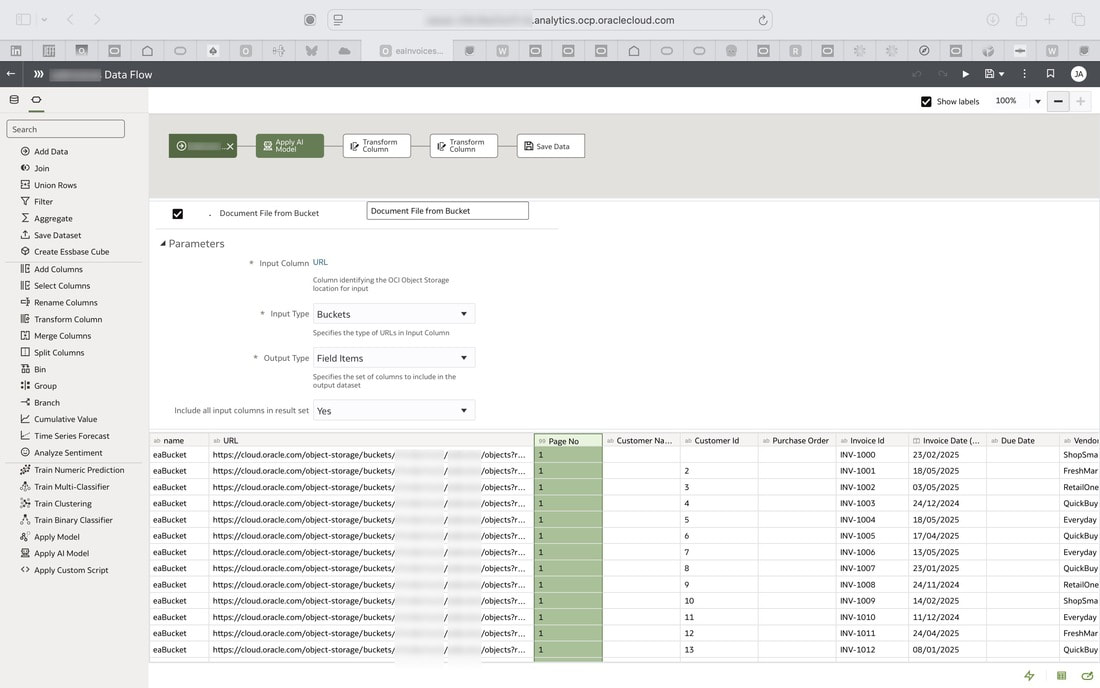
Once the data flow has been saved, it can be run to generate the output dataset. You can see a sample data visualisation workbook below based on the output dataset with some insights of the information derived from the invoices.
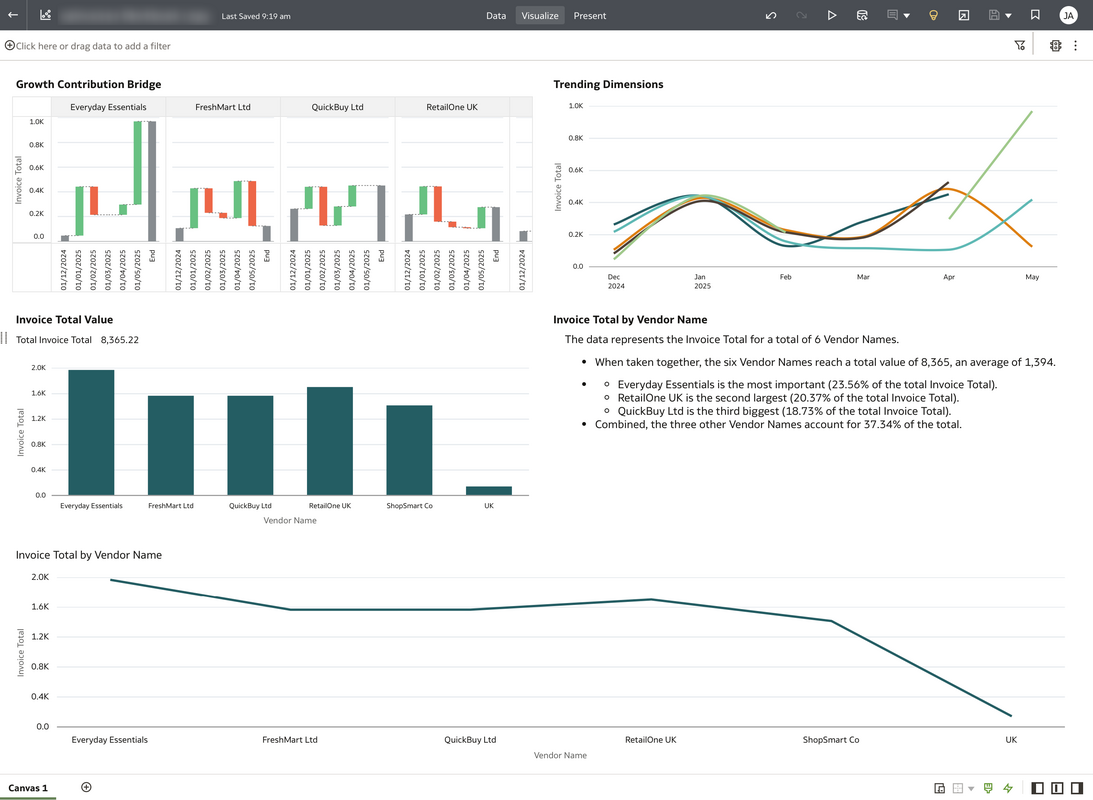
Tips and tricks for working with unstructured data in Oracle Analytics
Working with unstructured documents—especially at scale—introduces its own set of quirks. Here are some practical insights to help you get the most out of the AI Document Understanding feature in Oracle Analytics:
Use Document Batching Strategically
Oracle Analytics currently imposes a 10,000-row processing limit per run. If you’re working with high volumes:
- Break documents into batches and use multiple data flows.
- Consider filtering by date or document type.
Reuse and Schedule Data FlowsOnce you’ve built a data flow that works, save it and schedule it to run regularly:
- Use the built-in scheduler in Oracle Analytics.
Start Small, Then Scale
Try a proof-of-concept with 10–20 documents first:
- Test how accurate the model is.
- Check how the data appears in the dataset.
- Adjust your approach based on results—especially if OCR noise is high.
Resources
Official Documentation
Some YouTube videos from the Oracle Analytics channel:
Gotchas, Limits and Tips
- Bucket URL Must Be Copied from Browser
The most confusing part of this setup is finding the correct OCI Object Storage bucket URL. It’s not visible anywhere in the console UI—you must copy it from the bucket’s detail page URL in your browser. - 10,000 Document Row Limit
There’s a hard limit of 10,000 document rows per data flow run. If your use case involves large volumes of documents, you’ll need to split your data or automate batch runs accordingly. Note that this limit is even less when a custom model is used. The limit in this scenario is 2,000 documents. - Document Layouts Matter
The AI model is pre-trained for certain layouts (e.g. invoices, forms). Custom layouts may yield mixed results, and you may need to experiment with field mappings to improve outcomes. - Use Tags for Traceability
Tag your buckets and policies in OCI with labels like oac-ai-docs so they’re easier to audit and maintain.
Conclusion
Oracle Analytics’ AI Document Understanding feature bridges a crucial gap between unstructured documents and visual analytics. With a few setup steps—bucket creation, IAM policy configuration, model registration, and a simple data flow—you can surface hidden insights from documents that would otherwise sit untouched.
It’s a powerful tool, but one with nuances—such as the hidden bucket URL and processing limits—that are worth planning for. Still, for anyone looking to extend their analytics to the edges of their data estate, this capability opens the door. Oracle Analytics now makes it possible to integrate scanned documents, invoices, and other unstructured data sources directly into your dashboards—unlocking insights that were previously out of reach.